
This article isn't meant to be a guide of any sort, and sure won't teach you how to use Stable Diffusion (or any image generation AI) from scratch. See the Guides page for that kind of stuff. This is just a general, breezy tour for the uninitiated to get an idea of what it's really like to use AI to generate visual assets / art (I'm not getting into that philosophical debate, either). Now, let's jump in.
Why bother with AI image generation?
One of the things I hate most about making a website is finding images to put on it relevant to whatever I'm writing about. Browsing stock photo sites just bores me, and fills me with that dreaded feeling of "How many other schmucks are using this same image? Yeah, that's original."
So naturally, when AI image generation first started making the rounds, I was interested. I tried throwing some prompts at OpenAI's DALL-E image generation system, and was profoundly disappointed. It was beyond difficult to generate something original or interesting. Which makes sense, as AI are only trained on what they've been exposed to. Plus, I feel pretty comfortable saying DALL-E is the inferior model on the market at this point.
Then I heard about ControlNet. A fancy suite of tools that allows you to guide the image generation process when using Stable Diffusion AI models, allowing you to utilize an image generation AI to apply a new style or some final touches, but you are given far more control over subject matter, poses, and the like.
My initial attempts were met with sadness, failure, frustration, and a sudden-onset case of tourettes (I have the same reaction to networking hardware). I didn't even bother saving the attempts, they were so useless. "But Ryan," I hear you say, "aren't you some kind of computer graphics programmer?" The answer is yes, but not computer vision. That's a very different subfield of Computer Science, though there is some mild overlap. So I shelved it for a few months.
Once Stable Diffusion XL (SDXL) came out, I knew I had to take the leap and try it out. People were getting cool results, and documentation was getting better.
Total Control
The reality is, there is no one 'right' way to do things with Stable Diffusion, and there is a lot of experimentation involved. Under the hood, it's a lot of crazy math interacting in crazy ways, and through some good ol' fashioned spaghetti science, you can get some really neat results.
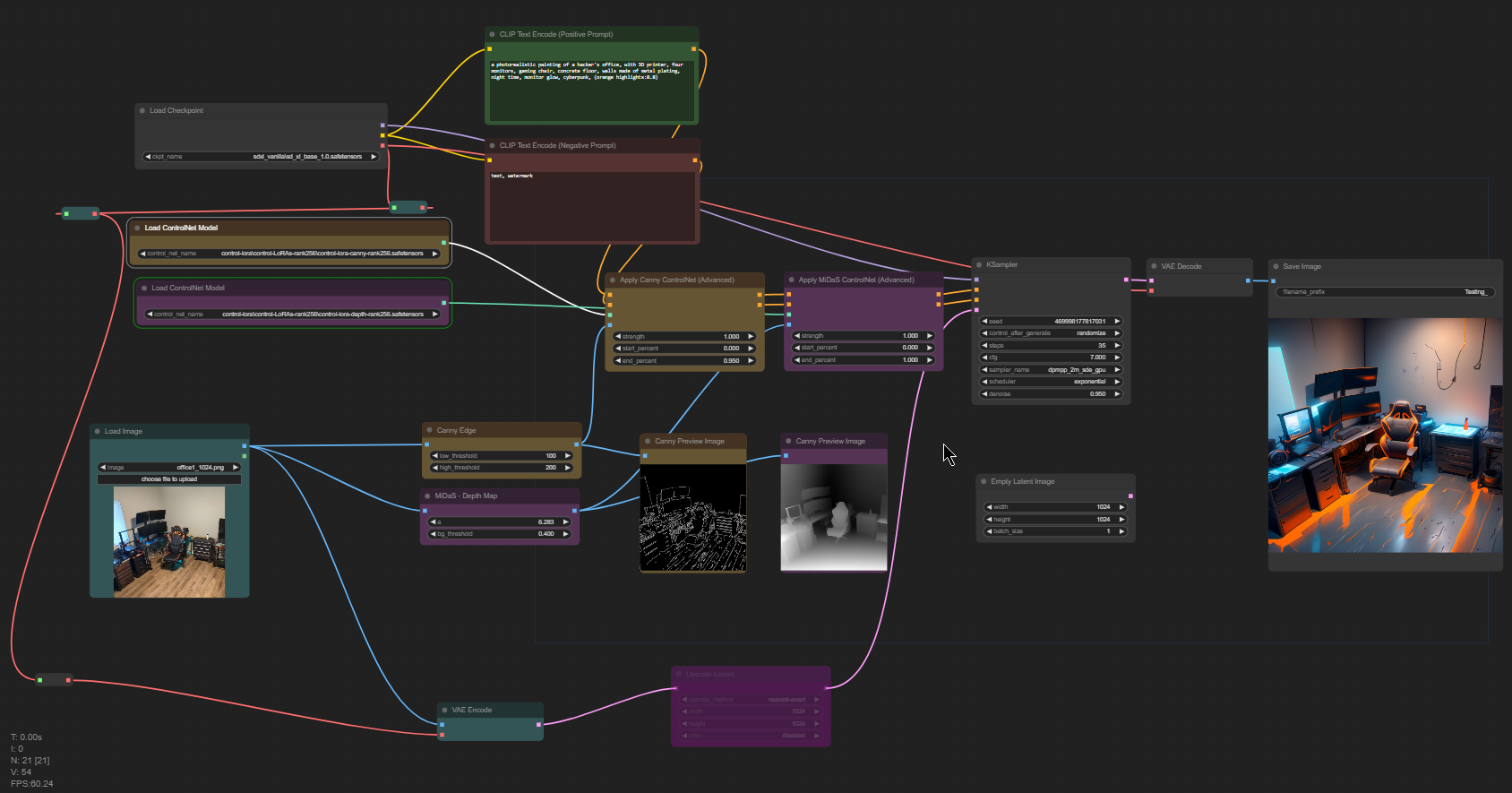
My 'weapon of choice' was ComfyUI, coupled with SDXL. I loaded them up, along with an edge detection ControlNet model and a depth map ControlNet model. You may be asking yourself, "Just what in the hell are those?" More on that in a minute.
Edge Detection
This is super cool. The Canny edge detection algorithm was developed by John F. Canny in 1986. A lot of oldschool algorithms have been getting dusted off with the advent of AI. It does pretty much what it says on the label: It finds the edges within your image. Below, you can see what edges the algorithm found in the photo of my office from the top of this article.

This image is fed into the AI through a ControlNet model. ControlNet models have basically been trained to recognize certain aspects of images, to help guide generating something new. In the case of the Canny ControlNet model, it's been trained on a bunch of images and their canny edge counterparts.
Depth Maps
A depth map is a special kind of image that shows how close or far something is from the camera's perspective, generated by analyzing a photo or piece of artwork. A more recent machine learning algorithm, MiDaS (MultIple Depth estimation Accuracy with Single network, ugh), happens to be really freakin' good at it. While this doesn't help guide the shape of an image as much as Canny, it can help inform things like lighting direction, luminosity, and shadow projection. Something to note is that both Canny and MiDaS can operate independently of each other, but by their powers combined you can get way cooler results. Below, you can see MiDaS' interpretation of that same photo of my office.

Inputs
So, for my inputs, I used those two images from my Canny and MiDaS algorithms, and then the following as my text prompt:
a photorealistic painting of a hacker's office, with 3D printer, four monitors, gaming chair, concrete floor, walls made of metal plating, night time, monitor glow, cyberpunk, (orange highlights:0.8)
So, basically, I just describe a combination of what is in the photo and what I'd like to see in the photo. I did tweak the prompt a few times throughout, but I'll spare you posting every variation. Please note that you can run the same prompt with different 'seed' values (a number thrown out by a random number generator) and get a completely different result. Below, you can see a few of the outputs I got from my generation attempts:



Where next?
As these tools continue to improve, I think they'll be a huge help to independent creatives. But they're not going to solve everything. If you have a piece of 'key art' for your business (that is, stuff that needs to look really, really freaking good like a book cover, or a movie poster), then you should hire an artist or graphic designer who knows what they're doing.
However, for generating throwaway marketing images, stock photos, or just cool assets to go with an article? Dude. Use AI. Most of the visual assets on this site are AI-generated. Are they as good as they could be if I hired an actual artist? Probably not. Are they better than I could have afforded to do myself for a website that generates zero income? You bet your ass they are.
Ladies and gents, that concludes our tour. If you're interested in diving deeper into understanding Stable Diffusion, I would recommend this fantastic YouTube playlist by Scott Detweiler. Alternatively, if you want to get your hands dirty, try playing with this public SDXL instance or StabilityAI's public demo for SDXL.